
In the previous post I’ve investigate the antagonistic relation between efficiency on one side and resilience on the other. As that is a pretty abstract subject, I tried to draw up a few simple charts to underpin the story of how efficiency, when taken to extremes, depletes resilience and ultimately promotes system failure.
 First, let’s think of a simple task, the problem to be solved, say: find a way to connect A with B. The solution space is defined by some other locations or nodes that you can use as way points. In reality, such solution spaces will be multidimensional, intertwined, messy, and even partially invisible. However, for the illustrative purposes of this post, I’d suggest the simple rectangular roster depicted on the right. You might think of the problem as a logistics task, transporting goods from one location to another. Or consider it a grossly simplified model of the internet: how to get information from A to B?
First, let’s think of a simple task, the problem to be solved, say: find a way to connect A with B. The solution space is defined by some other locations or nodes that you can use as way points. In reality, such solution spaces will be multidimensional, intertwined, messy, and even partially invisible. However, for the illustrative purposes of this post, I’d suggest the simple rectangular roster depicted on the right. You might think of the problem as a logistics task, transporting goods from one location to another. Or consider it a grossly simplified model of the internet: how to get information from A to B?
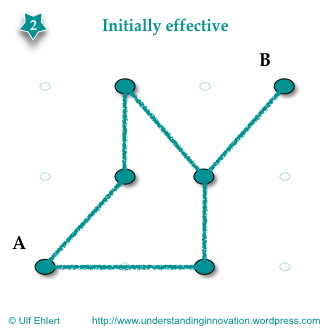 Of course there is no wrong approach to solve this simple problem. Any sequence of connections will get the job done, they will all be initially effective. So one potential solution would look like the chart on the right. It’s certainly not perfect, but it connects A with B, so it does solve the problem.
Of course there is no wrong approach to solve this simple problem. Any sequence of connections will get the job done, they will all be initially effective. So one potential solution would look like the chart on the right. It’s certainly not perfect, but it connects A with B, so it does solve the problem.
Now, if you were to activitate a transportation system based on this design, you’ll soon become aware of its weaknesses: your travel distances are unnecessarily long, and the duplication of paths causes some confusion as well. So you’ll soon think about making it work better, faster, handle more traffic at less cost: you’ll start looking for ways to make the system more efficient.
 At the same time and without you consciously realising, the alternative nodes start fading from your thinking. While they were part of the initial solution space, they are not part of the current system. So they are less and less relevant for the system-focused thinking. Over time, they’ll be forgotten. But that loss of alternatives is irrelevant for the efficiency-mindset.
At the same time and without you consciously realising, the alternative nodes start fading from your thinking. While they were part of the initial solution space, they are not part of the current system. So they are less and less relevant for the system-focused thinking. Over time, they’ll be forgotten. But that loss of alternatives is irrelevant for the efficiency-mindset.
In the next phase, you’ll then strive to make your system increasingly efficient. Again, there are different options, but in the end you’ll probably take a strategic decision: maintaining two separate routes seems too costly, hence you pick a preferred route and handle all traffic through that connection (as depicted on the right). Traffic on that route will increase, the system is humming and buzzing, that’s what you want. The other route is forced to leave the initial system, the connections will fade and be forgotten over time.
 Now, you can continue on that quest for efficiency. You might take another strategic decision: cut out that detour and replace that with a new, shorter, more efficient connection. Again, that’ll likely increase traffic even further and give you what you want. And again, another node is forced outside the system, and another connection will be forgotten over time. You have created a very efficient system, a well-oiled machine that does exactly what is required. So you have achieved your goal. However, that system has lost its resilience. Over time, and as a direct, even though unintended, consequence of your strategic decisions in the quest for efficiency, your system has lost the ability to bounce back.
Now, you can continue on that quest for efficiency. You might take another strategic decision: cut out that detour and replace that with a new, shorter, more efficient connection. Again, that’ll likely increase traffic even further and give you what you want. And again, another node is forced outside the system, and another connection will be forgotten over time. You have created a very efficient system, a well-oiled machine that does exactly what is required. So you have achieved your goal. However, that system has lost its resilience. Over time, and as a direct, even though unintended, consequence of your strategic decisions in the quest for efficiency, your system has lost the ability to bounce back.
Within this system, every node and every single connection is on the critical path. That’s perfect for efficiency, but it’s only effective as long as the current situation is perfectly stable and does not change. A bad awakening will come:
- if any of the perfectly busy building blocks of your system fails, or
- if any of the connections breaks.
The reasons that trigger such initial failures can be manifold, they could be major (like an earthquake), they might be rather minor (like a small road accident that happens to block the access to one of your sites). But regardless of the scale of the trigger, in such a situation the entire system will fail: a fairly minor reason would cause a major shock. Because there are no alternatives to re-route the traffic, and no spare components to pick up some of the functionalities, the system will be out of service for as long as it takes to fix the initial trigger problem. No matter how much time and energy that would require, the system has no alternative: it was perfectly efficient for that one purpose in that one specific way, but it is entirely ineffective in an environment that changes only mildly.
In the end, we are back to the conclusion of the previous post: efficiency cannot be an end in itself, it must be seen embedded within effectiveness, and balanced with the need for resilience. Ultimately, we must afford ourselves some level of inefficiency.
